PostgreSQL as the substructure for IoT and the next wave of computing

How PostgreSQL accidentally became the ideal platform for IoT applications and services.
Computing, like fashion and music trends, advances in waves. (Or, if you prefer a software development metaphor: Computing evolves via major and minor releases.)
From mainframes (1950s-1970s), to Personal Computers (1980s-1990s), to smartphones (2000s-now), each wave brought us smaller, yet more powerful machines, that were increasingly plentiful and pervasive throughout business and society.

We are now sitting on the cusp of another inflection point, or major release if you will, with computing so small and so common that it is becoming nearly as pervading as the air we breathe. Some call this the “Internet of Things”, “Connected Devices”, or “Ubiquitous Computing.”
With each wave, software developers and businesses initially struggle to identify the appropriate software infrastructure on which to develop their applications. But soon common platforms emerge: Unix; Windows; the LAMP stack; iOS/Android.
Today developers of IoT-based applications are asking themselves an important question: what is the right foundation for my new service?
It is too early to declare a winning platform for IoT. But whatever it is, we believe that its substructure, its foundational data layer, will be Postgres. Here’s why.
A closer look at IoT data
Popular science fiction often depicts a future filled with machines, some benevolent (and some less so).
But it turns out that the machines already surround us. In fact, last year was the first year that connected devices (not including computers and smartphones) outnumbered the human population on this planet.
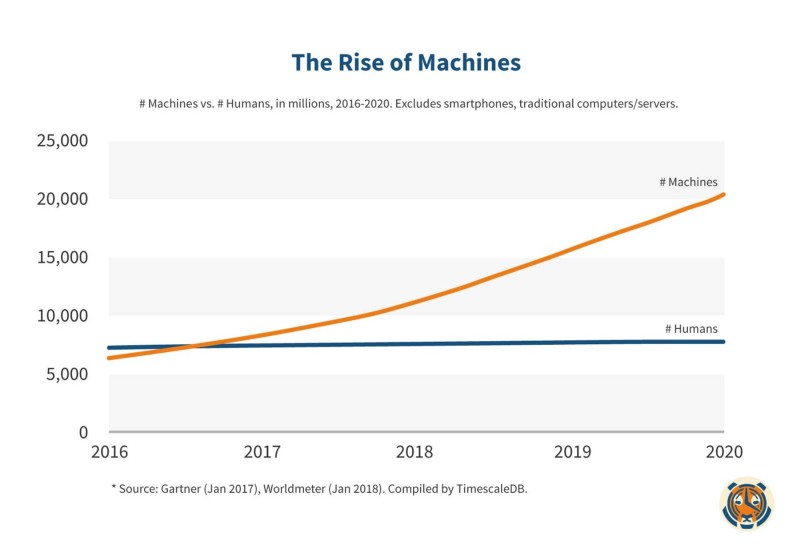
As a result, large amounts of machine (or IoT) data are now showing up in more and more places:
- Industrial machines: How most of our things are made.
- Transportation and logistics: How we move people and things across our world.
- Building management and the Smart Home: How we live in and secure our homes and businesses.
- Agriculture: How we feed the planet.
- Energy & utilities: How we power our world.
- (And so many more)
But what is this machine data? Let’s look at a simple example:
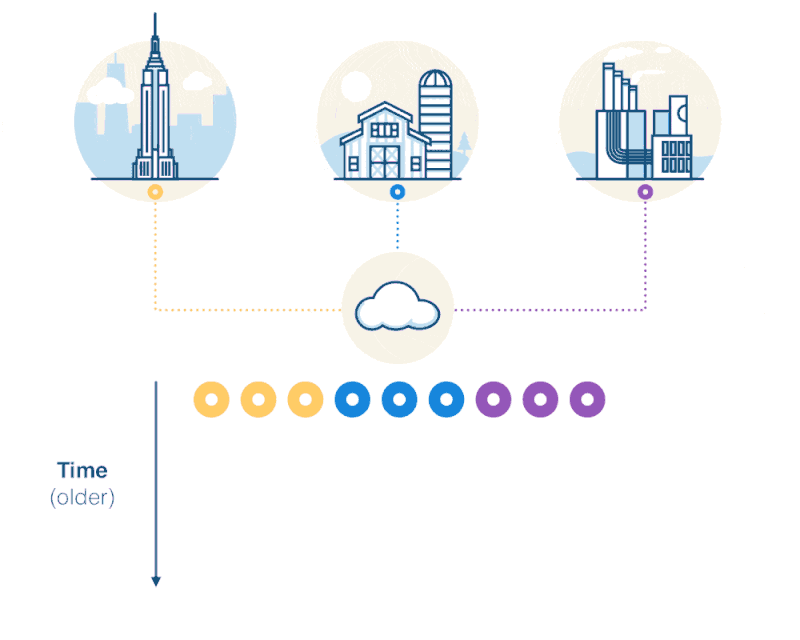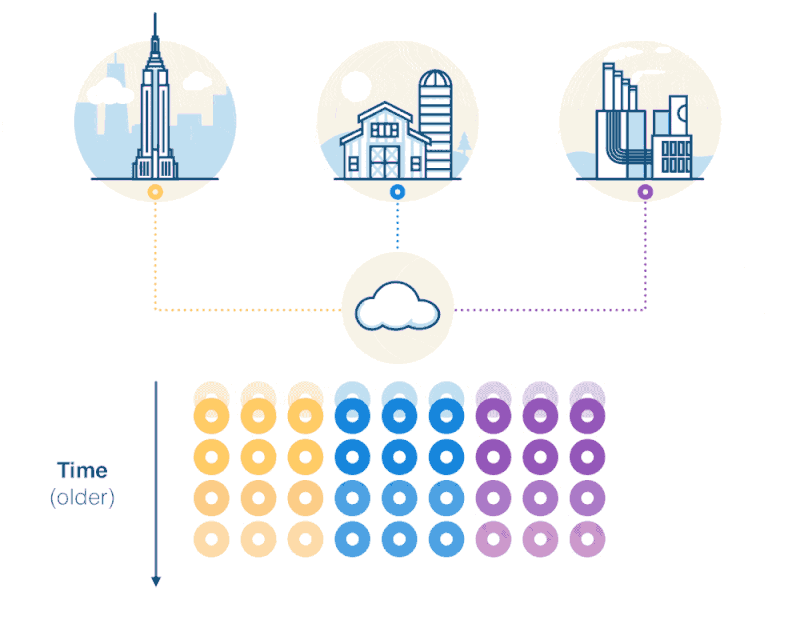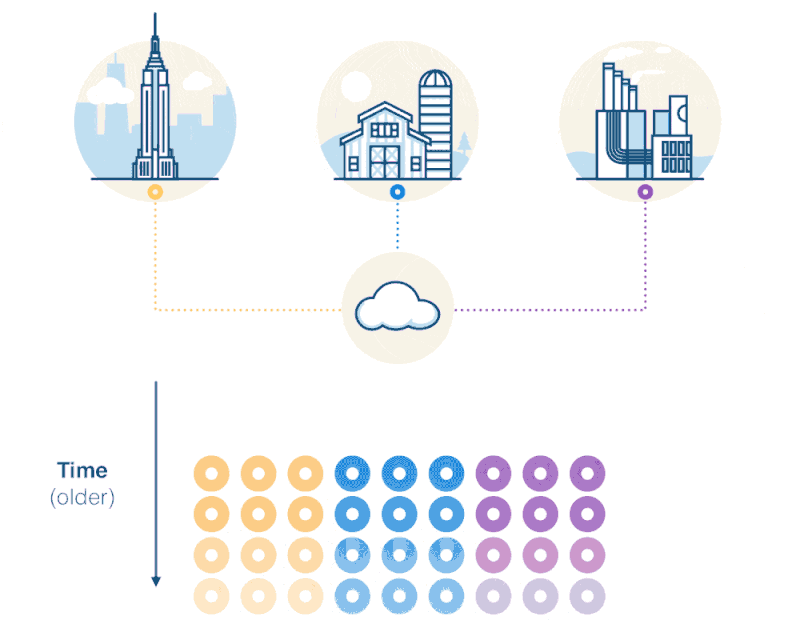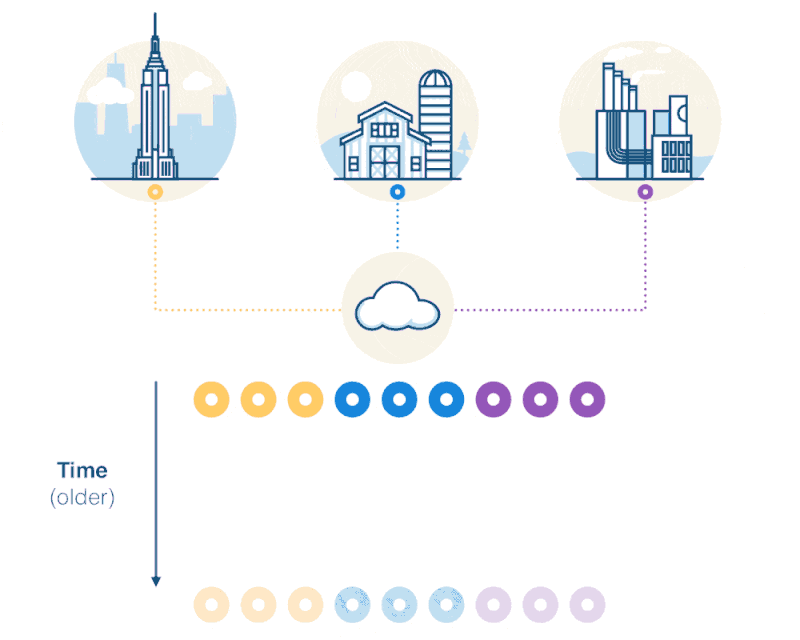
Here we have data generated from three sources: a building, a farm, and a factory. Data arrives periodically, ordered by time. When a new data point comes it, we add it to the existing dataset.
As you can see, as we collect machine data, we build a time-series dataset.
But let’s dig a little deeper with another example:
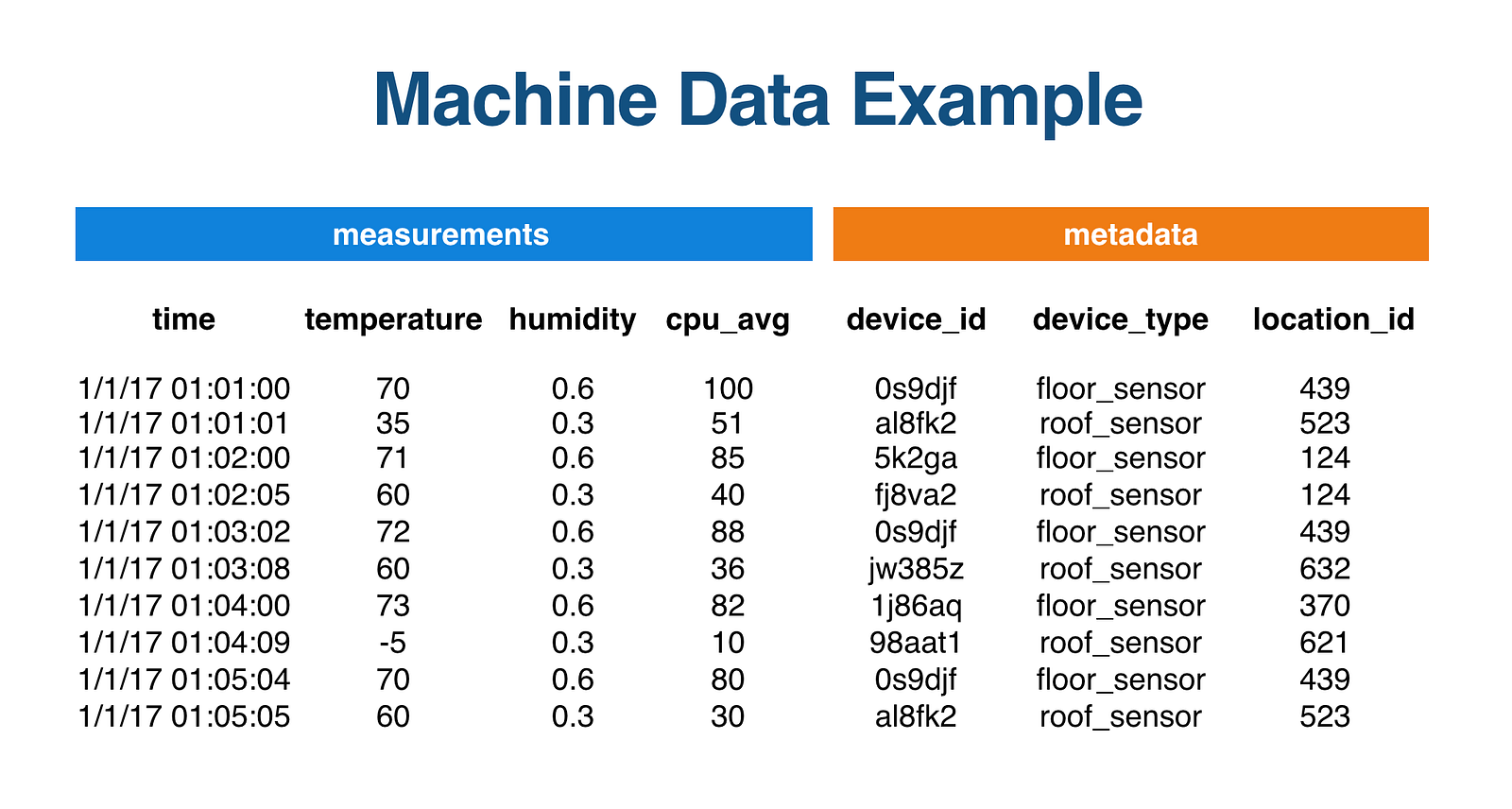
Here we see that the dataset is a set of measurements collected over time. Again, the dataset is time-series in nature.
But there’s also additional metadata describing the sources (whether sensors, devices, or other “things”) of those measurements. And if we look closely, it appears that the metadata, currently recorded on each reading, looks relational. In fact, one could easily normalize the dataset, with each row containing foreign keys to separate metadata tables. (In our example, we could create additional “devices,” “locations” or even “maintenance” tables.)
In other words, IoT data is a combination of time-series and relational data. The relational data just describes the things that generate the time-series.
Which suggests that for IoT we might want a relational database. Like Postgres.
Why use Postgres for IoT?
There are a lot of reasons why one would want to choose Postgres for IoT:
- Relational model + JOINs: As we just saw, the relational model lends itself well to IoT.
- Reliability: Decades of software development and production deployments has led to a rock-solid database.
- Ease of use: A query language (SQL) that developers and business analysts already know how to use, and a database the DBAs already know how to operate.
- Broad ecosystem: The largest ecosystem of compatible visualization tools, backend infra, operational utilities (e.g., backups, replication), and more.
- Flexible datatypes (including JSON): A broad set of datatypes, including (but not limited to) numerics, strings, arrays, JSON/JSONB.
- Geospatial support via PostGIS, which adds support for geographic objects and location-specific queries.
- Momentum: Postgres has perhaps the most momentum of any open source database at the moment (which is why DB-Engines named Postgres as the top DBMS of 2017).
But why isn’t Postgres already used for IoT?
Some people already use Postgres for IoT. If you have low insert rates and are only storing a few million rows of time-series data, Postgres may meet your needs out of the box.
But there is a reason why Postgres isn’t already the default database for these kinds of workloads: Postgres does not naturally scale well.

IoT workloads are typically characterized by high insert rates that create large datasets. And as one can see in the graph above, as the dataset grows, insert performance on Postgres drops precipitously — a clear incompatibility.
This drop-off represents the performance trade-off between memory and disk. Beyond a certain size, data and indexes no longer fit in memory, which requires Postgres to start swapping to disk. (A longer explanation here.)
(And it turns out that Postgres 10 does not solve this problem.)
So how should one scale Postgres for IoT data while retaining all of its benefits?
Our former life as an IoT platform
To us, scaling Postgres for IoT workloads is more than an academic question. It’s a real problem that our company faced in a former life.

Our company first started as iobeam, an IoT data analysis platform. And we were moderately successful, collecting large amounts of machine time-series and relational data for our customers. And we needed to store that data somewhere.
Yet we found that the world of databases at that time effectively only offered two choices:
- Relational databases (E.g., PostgreSQL, MySQL) that were reliable, easy to use, and performant, but scaled poorly.
- Non-relational (aka “NoSQL”) databases (E.g., Cassandra, InfluxDB) that scaled better, but were less reliable, less performant, harder to use, and did not support relational data.
But given that our IoT workloads were comprised of both time-series and relational data, our only choice was to run two databases. This led to other problems: it fragmented our dataset into silos, led to complex joins at the application layer, and required us to maintain and operate two different systems.
What we really wanted was the best of both worlds: something that worked like Postgres, yet scaled for IoT workloads. And given that our Engineering team is led by a Princeton Professor of Computer Science, we decided to build it ourselves.
And then, after hearing from a multitude of other developers who were facing the same problem, we pivoted from an IoT platform to an open source time-series database company, launched the product (April 2017), and then raised $16M (Jan 2018) to grow the business.
Scaling Postgres for IoT workloads
Here’s how we scaled Postgres for IoT:
- We identified the main bottleneck: the time spent swapping parts of a dataset that could no longer entirely fit in memory to/from disk.
- We then recognized that time series workloads had very different characteristics versus traditional database (or OLTP) workloads:

As one can see, traditional database workloads tend to be update-heavy to random locations, with updates often requiring complex transactions.
For example, here’s the canonical bank account example: If Alice sends Bob $10, then the database needs to atomically debit and credit two otherwise unrelated accounts/records.
But on the other hand time series workloads tend to be insert-heavy, largely in order, with simple transactions. The time-series version of our same bank account example would look like this: insert a row that represents a $10 transfer from Alice to Bob, timestamped to now.
Insight #1: Right-sized chunking
Out of this came insight number one: we could partition our data by time such that each individual partition, or chunk, is right-sized so that all data and indexes fit in memory. If sized appropriately, swapping would be minimized (or even eliminated for the most recent or “hot” chunks).
But when your data is heavily partitioned, that leads to other challenges: managing those partitions, querying across partition boundaries (often requiring complex JOINs), inserting to the right partition, creating new partitions as necessary, etc. This can be a major headache.
Insight #2: The Hypertable
Then came insight number two: the Hypertable, a single virtual table across all partitions that operates like a regular Postgres table and hides all complexity from the user.
Query data from the Hypertable, and it will efficiently identify the right partitions that contain your data; Write data to the Hypertable and it will route tuples to the appropriate partition (and create new ones as necessary); Create indexes/constraints/triggers, manage your schema, all at the Hypertable level, and all changes are propagated to the appropriate chunks.
Now what should the interface to the Hypertable look like? At first we were tempted to create our own query language. But then we were struck with the sheer impracticality of that approach: we’d have to create whole new connectors to every visualization tool, backend component, etc., let alone having to educate entire populations of developers.
Insight #3: Embrace SQL
But then we realized that there was a much simpler path: just embrace SQL. Everyone knows SQL, there is plenty of literature on how to express queries in SQL, and there is a plethora of tools that speak SQL. And for any time-series analytics that are currently suboptimal in SQL, SQL (and PostgreSQL) can be easily improved, via UDFs and query-planning/query-execution level optimizations. (Some examples here.)
And then we took this philosophy one step further and fully embraced Postgres by packaging our work into a Postgres extension. So now anything that works with Postgres (e.g., visualization tools, admin tools, backup/restore utilities, data infra components, etc.) would work with our new time-series database.
At a high-level, here’s the representational model we built:
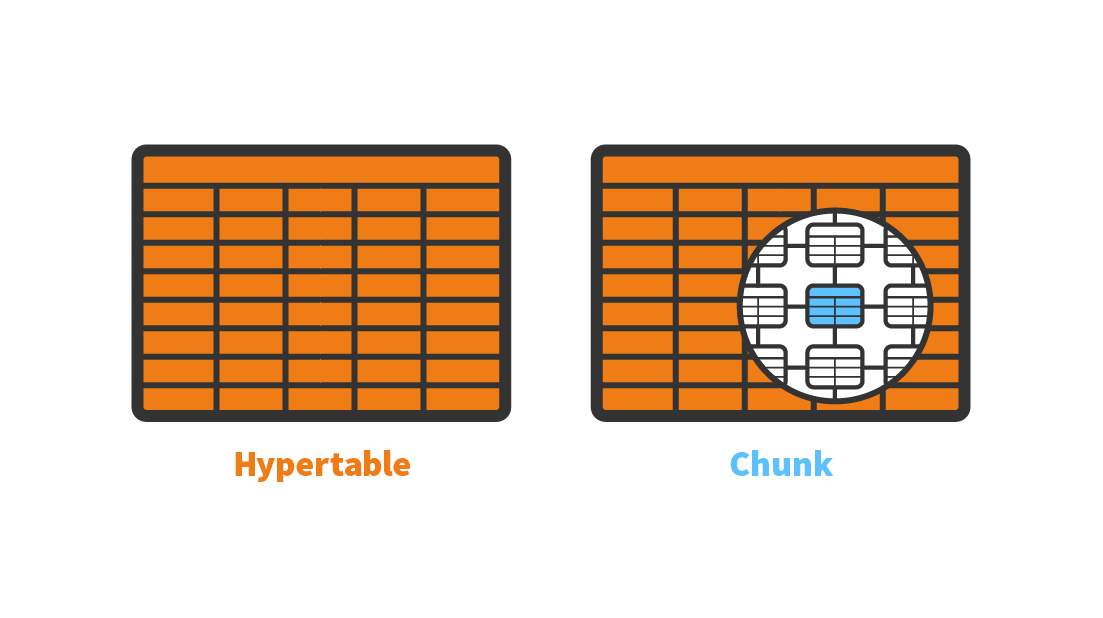
Of course, the devil is in the details: chunk management, efficient queries, fast tuple routing, enforcing the Hypertable-as-a-vanilla-table guarantee also required a lot of work at the C and PL/pgSQL levels to get right. (More here.)
Our results: 20x higher inserts, 2000x faster deletes, 1.2x-14,000x faster queries
The benefits of this architecture can be seen in the results:


In addition, thanks to this architecture we are able to scale a Hypertable up to tens of terabytes, while achieving hundreds of thousands of inserts per second, all on a single node. (More on our benchmarks vs Postgres and vs Postgres 10.)
This design also allowed us to retain all of the benefits of Postgres that we listed earlier:
- Relational model + JOINs: Hypertables live alongside “vanilla” relational tables
- Reliability, ease-of-use, ecosystem: Our design doesn’t muck with the underlying storage layer, and maintains the same SQL syntax, so it operates and feels just like Postgres.
- Flexible datatypes (including JSON), geospatial support: Similarly, this approach maintains compatibility with all of the Postgres native datatypes and extensions like PostGIS.
- Momentum: As an extension (i.e. not a fork), the design is compatible with Postgres mainline, and will continue to benefit from the continued underlying improvement in Postgres (and also allows us to contribute back to the community).
The Accidental IoT platform?
Now that we can scale Postgres for IoT, we can also choose from a variety of applications and tools to use on top: e.g., Kafka, RabbitMQ, MQTT, Apache Spark, Grafana, Tableau, Rails, Django… the list goes on and on.
In other words, even though Postgres is multi-decade-old open source project, it has now accidentally become the ideal platform for IoT and the next wave of computing.

If learning about our journey has been helpful, you’re welcome to follow the same path and scale Postgres yourself. But if you’d rather save time, you’re also welcome to use TimescaleDB (open source, Apache 2). The choice is yours. But we are here to help.
Like this post and interested in learning more? Check out our GitHub and join our Slack community. We’re also hiring!




